本章開始進入Shell Scripts的程式設計,因為Linux Shell的種類相當多,故筆者僅挑選預設的Bash Shell 及 學術界常會使用的 C Shell (/bin/tcsh )來說明與對照,在此先說明。至於 Scripts 的概念,在前章就已經說明過,可視為前壹章的各項指令之組合,在令其在執行檔案裡,依序執行,如前章所看到的 /etc/profile 檔案,在其他軟體上,有點類似巨集(macro)的執行檔,或是MS Windows的批次檔(Batch)。先建立此概念後,我們可以先在Terminal的命令提示字元,使用 for 指令,如圖2-1,在 shell scripts 內為了重複做一件事,而僅修改某些變數值,我們會利用所謂的迴圈(loop)方式來完成,而 bash shell 內常用的是 for 或是 tcsh/csh shell 內的 foreach。

(圖2-1)
圖 2-1第一個指令輸入 for 的宣告,後面接著 seq 為變數名稱,為了逐次接收 in 後面之陣列值(http://www.gnu.org/software/bash/manual/html_node/Arrays.html)(註:若加了 ; 則 do 便可寫在同一行),接著 > 的提示字元的等待輸入,便是還沒遇到 done 指令來結束 do 的動作,控制此提示字元的環境變數為 PS2。,此例的 seq 值,依序為第一次讀入 first 字串並存入變數 seq 當其值,接著second、third,從 echo $seq 可以看出,接著設定一個變數 file 其值為 my開頭字串,緊接變數值 $seq(first、second、third),再接固定的 script.sh 字串,接著利用echo指令,印出變數值$file,檢查是不是我們預期的字串值(註:如果想要暫停,讓使用者可以看清楚再繼續,可以加上指令sleep 3,表示畫面停止三秒鐘),接著利用 touch 指令產生 $file 字串值的檔案,再將其利用 chmod 指令,u+x 參數為令僅創立此檔的使用者帳號可執行(若要改為同群組可執行,參數需改為 g+x)。故可看到第二個指令輸入 ls,便列出自動批次產生的shell執行檔了。
以上其實就是 Shell Script 的程式設計之一,只是我們利用Terminal的互動介面。若要把指令全部打完,再一次執行完成,顯示要的結果呢?那就是把它們放在可執行檔案,再直接執行,或是利用 source 的方式執行,也就是所謂的script(中國都稱腳本兒,台灣一般稱指令稿),我們馬上就來試一試吧!
首先,為了確認待會的Script有執行成功,請利用指令 rm -f my*script.sh ( * 號代表my 與 script.sh字串之間無論間隔多少字元的檔名,都屬於此類,需被刪除。若要精確字元數,請使用 ?,一個 ? 代表間隔一個字元),刪除剛剛產生的.sh檔,並且利用指令 vim pro_script.sh,來產生檔名稱為 prod_script.sh 的 script檔,並在裡面鍵入上面的圖2-1所用的指令,如圖2-2

(圖2-2)
儲存上圖離開後,再利用指令 chmod u+x prod_script.sh ,即可在命令提示字元下鍵入 ./prod_script.sh 執行,若是只想直接打 prod_script.sh ,請讀者記得要在 ~/.bash_profile 下,加入 export PATH=$PATH: . ,. 表示把現在的位置,亦加入搜尋路徑內,export宣告環境變數,自訂變數無需加宣告保留字。(2021.10.07更正export說明,以下自訂變數宣告請直接去除export開頭)
眼尖的讀者會發現,為何圖2-2會出現第一行的字串,其實這是 Script 很重要的初始宣告,宣告給電腦系統知道,以下皆使用 bash 的指令或語法完成。若無此宣告,通常需要使用 bash prod_script.sh ,才有辦法執行你撰寫的 Script。往後的範例,只要是循序跳動的數字值,其變數名稱會如一般程式設計習慣,使用 i 、j、k 來代表 ,以防止跟 Shell 保留字或指令衝突,如 seq 其實為 shell 內的指令。利用指令 seq 1 10,則會產生 1 2 3 4 5 6 7 8 9 10,的數列,讀者可以自行 man seq 來了解詳細參數。
接著我們再試著產生今年度(2016)的所有天,每天一個資料夾,每個資料夾內,放入以時間為檔名的資料檔,資料內容為隨機產生的時間序列資料,結果如圖2-3-1,script為圖2-3-2,為了說明方便,筆者另用加了行號的圖2-3-3來說明,除顯示行數與顏色,與圖2-3-2內容皆同。

(圖2-3-1)

(圖2-3-2)

(圖2-3-3)
圖2-3-3第1行為宣告何種 shell,第3、4行為利用 date 指令,來產生我們要的表示方式,並分別指派給 yr 與 ed 變數,說明如下:(export為宣告環境變數),我們直接變數名稱=變數值,請記得=的兩邊,千萬不能有空格
yr=`date +%Y -d "now"`
/* 利用date指令與參數 +% 格式化輸出,+%Y 是印出西元年全部數字,2016,而非16 ( 僅列出後兩數字要換成 +%y ),並利用 -d 參數來使用字串指定各種日期,若是現在時間,則亦可以不需使用 -d "now",使用此指令需確認是否系統時間跟網路標準時間(https://en.wikipedia.org/wiki/Network_Time_Protocol)一致。export 亦可換為 let 或 declare */
ed=`date +%j -d "$yr/12/31"`
/* 可指定日期為今年度的12/31,且要格式化輸出 Day of Year,因2016為閏年,故 ed 的值為 366,-d 參數所接的字串值,可以如以英文表達來獲得日期,如$date %Y-%m-%d -d "100 days ago",可以得到今天(2016-6-1)的100天前為(2016-02-22)。常用的 +% 參數有, +%D 直接列出 month/day/year,+%H:%M:%S,可以列出 hour:minute:second,%s (小寫),為列出從1970-01-01到目前的秒數,通常拿來做 timestamp以辨別不同時間的工作所產生的結果。這對於學術界的資料處理,是很重要也常用的指令,有興趣的讀者,可以藉由 man date ,來了解更多參數與應用。 */
第6到8行,為防止在現在路徑下,已經有 $yr (2016)當名稱的資料夾,故屬於防呆判斷(例外處理),跟18到20行、第26到28行大同小異,只是判斷資料夾存在的參數為 -d ,判斷檔案存在的參數為 -f。
接著利用 cd 進入資料夾。再接著,我們要先產生 "$yr.$ed "為名稱的資料夾,如 2016.001,連續產生到2016.366,所以第11行的 for 迴圈為利用 seq 指令,產生1到366的數字,並逐次把數字當成變數 i 的值,且為了要維持三個字元讓排序可以完全依照 001 至 366,故第13行使用 printf 指令,把 i 的值格式化成三個字元值,並若為1-10則補上1個0,若為11-99則補上2個0。
第14行,為筆者習慣把指令的變數值,可以來除錯,是否為預期的變數值,故確認無誤後,就用 # 讓 echo 失效,然後再進入已產生的 $yr.$ed 。
我們再利用指令來產生我們要的兩個檔案 "$yr.$doy.TS.data"、"$yr.$doy.TS.Norm.data",如2016.001.TS.data、2016.001.TS.Norm.data,內容為四個欄位,分別為時間(0 - 1秒,以0.01為間隔)、x方向的位移、y方向的位移、z方向的位移(以上位移皆利用 $RANDOM 亂數變數產生,該變數可產生 0 ~ 32767 的正整數,利用 % (取餘數)的運算,就產生位移為 0~10 的值(第32到34行),再利用複寫的轉向子 >> 逐一累加入檔案 "$yr.$doy.TS.data" )。第30行至第54行,便是 for 迴圈利用 seq 指令,產生時間 0至 1秒的101筆紀錄值(如圖2-4,為利用 LibreOffice Calc 軟體,畫出 2016.001.TS.Norm.dat 內,分別在 x、y、 z 方向隨時間的(亂數)位移,因各方向數值已經對本身數值群組的最大值做正規化(normalize),如圖2-3-3第45行,故位移數值皆落在0 ~ 1 之間,未正規畫前的數值存放於 2016.001.TS.dat )。
第38到40行,便是利用排序指令 sort,並配合 head 指令來找尋最大值,說明如下:
xmax=`awk '{print $2}' $dfile | sort -nr | head -1` /* 為利用 awk 將檔案名稱為變數值 "$dfile" 內的第二欄位資料印出,並傳給 sort 利用參數 -n (數字排序),-r (由大至小),排完後,再把排序結果傳給 head 指令,利用參數 -1 (hyphen one)(也可用 -n 1),來印出第一個值,此值為最大值,其他找 y、z 最大值亦利用同方式 */
第44到45行,為將找到的最大值,對原本的數值做正規化至0 ~ 1 之間的數值,再利用轉向子 >,一次寫入變數檔案名稱 "$ndfile",說明如下:
eol=`cat $dfile | wc -l` # 利用 cat 與指令 wc -l 來計算檔案內容總行數
awk -v a=$xmax -v b=$ymax -v c=$zmax -v l=$eol '(NR<=l) {printf \
"%5.2f%7.4f%7.4f%7.4f\n" ,$1,$2/a,$3/b,$4/c}' $dfile > $ndfile
/* 上方多的符號 \ ,僅因指令太長,故用此符號銜接。awk 可以利用參數 -v 來傳遞 shell 的變數值,變成 awk 的變數值,故本例可替換成 awk 的變數 a、d、c。NR為 awk 的保留字,代表著現在讀取的行數,因 awk會從檔案內容第一行開始讀取,故筆者設定讓它讀到最後一行後,接著利用格式化 prinf 列出( %5.2f為第一欄印出值形式為浮點數(就是包含小數點的數值,資訊科學裡一般稱為floating point(https://en.wikipedia.org/wiki/Floating_point),往後不再贅述),共 5 個字元,包含小數點後顯示 2 個字元,故 %7.4f,共7個字元,包含小數點後顯示4個字元),\n 為斷行字元(new line),隨後,第1欄,第2欄除以第2欄最大值,第3欄除以第3欄最大值,第4欄除以第4欄最大值,接著把結果一次寫入 $ndifle,若想同時將結果列在螢幕畫面,與寫入檔案,可將 > 指令改為 | tee ,就可以同時顯示螢幕( stdout/1,https://en.wikipedia.org/wiki/Standard_streams)與檔案 */
第47到51行,為利用 awk 指令求平均值,先利用累加方式求如第一欄總和 sum+=$1 (為 sum=sum+$1 表示法,在很多程式設計語言常用 ),在END 後,NR便為讀取的最後行,故直接將總和 sum 除以 NR得到平均數值,因僅測試,故筆者便將其 #,使指令無作用。
接著第53行與第56行為跳出兩層資料夾,使執行script結束後,回到原本執行的路徑下,第57行就令其印出如"執行完畢"的字串(說實在,大部分是耍帥用,就端看讀者個人心情)。

(圖2-4)
經由上面的經驗,看起來找數值陣列的最大、最小、平均等基本統計值,似乎很常用到,那我們就來寫一個 script,可以讓我們可以藉由給定參數 (資料檔案名,資料第幾欄數值,需算何種統計值),把這些常用的計算函數統整,並可以依使用者需求選擇,來印出我們要的計算結果,如圖2-5。

(圖2-5)
圖2-5大致上可以分成6個區塊(block)來說明,承上述,為了達到可以重複使用來直接計算一群數的最大值、最小值、平均數、標準差,筆者設計了一個 cal_statis.sh 的 script,並用指令 chmod u+x cal_statis.sh 與設定 export PATH=$PATH:~/Desktop/myfolder,詳細便不再贅述了,直接看 cal_statis.sh 的內容。最上方第一行為宣告,之後篇章也都不贅述。
第 1 區塊為,執行 cal_statis.sh 與接其後面的參數數目為 3 個,為了確保使用者輸入參數數目為 3 個,則使用指令 if [ $# != 3 ] 來判斷,在此的 # 代表標準輸入(stdin,如利用鍵盤輸入)的數目,其值便為 $#,並非說明,請讀者要熟記。當數目值不等於 ( != ) 3,便印出說明再利用指令 exit 跳出 script 。(註:$# 如一般程式語言裡的 argc(argument count),而 $1,則為一般程式語言裡的 argv[1] (argument variable, index 1)。$# 用來計算外部輸入的參數數目,$1 為接收輸入的參數值,$0 為shell 的檔案名字 ),其他 $ 特殊用法,如 $$ 代表 shell 的 PID(process ID),$! 為最後一個背景執行工作的 PID,$?為最後執行的命令返回值,$* 與 $@ 為方別用"..."與" "..." "..." "的不同方式印出參數值。
第 2 區塊為宣告標準輸入的值,可以當成那些變數值,第 1 個輸入給 "$dfile",代表要操作的 資料檔名,第 2 輸入給 "$col",代表要操作的資料欄位,第 3 個輸入給 "$method",代表要使用的計算方法。
第 3 區塊為防止例外錯誤,僅為了防止輸入錯誤的檔案路徑。
第 4、5 區塊亦分別為防止欄位數非數字,與大於最大欄位數而發生程式執行錯誤,說明如下
if [ ! -n "$(echo $col | sed -n '/^[0-9]\+$/p')" ]
/* 為利用 -n 判斷是否空值,接著為利用 sed 的搜尋但不取代的能力,sed環境內參數 -n 為安靜模式,搜尋條件從 ' 開始,條件給在 / / 之間, ^[0-9] 為搜尋起頭為數字,接著 \+ 為後面接著的字元也是要數字(註:請參閱 Basic RE 與 Extended RE 的差異,https://www.gnu.org/software/grep/manual/html_node/Basic-vs-Extended.html),再來比對到 $ ,代表結尾也要是數字;p為 sed 的命令,表示若有符合搜尋條件,則印出數值。讀者看到這裡,可以回想一下前面章節,是否很像提過的正規表示式的方式呢? */
fn=`awk 'END{print NF}' $dfile` #利用 awk 的END{},來印出最後一行的欄位總數NR
if [ $col -gt $fn ] #若從外部輸入的數字,大於欄位總數,則接著印出錯誤訊息,並離開script
接著用 echo 印出 $dfile $col $method 值的指令,已用 # 變成說明,這提醒讀者寫程式時,留個好習慣。進入主要程式處理前,要先測試所得到的變數值,是否皆是你的預期值,不然垃圾參數輸入,垃圾結果輸出 (Garbage in,Garbage out)。
第 6 個區塊,為 case 指令的宣告,一般用於關鍵字的判斷與分類處理,筆者在此僅分成 max、min、avg、stdev,若不屬於上述四類,則會跳至 * 類別,並印出錯誤訊息。max 與 min 類別,分別計算最大與最小值,計算的方式在上一個 script 有說明,min 僅差在 sort 參數只用 -n,便為預設將數列從小排到大。avg 類別為計算數列平均值,上一個 script 亦有說明,便不在贅述,stdev類別則用來計算標準差(standard deviation, https://en.wikipedia.org/wiki/Standard_deviation),說明如下:
mean=`awk -v x=$col '{sum+=\$x}END{print sum/NR}' $dfile`
/* 利用 awk -v 來傳遞外部變數,當成 awk {}內運算的欄位變數,故請讀者注意要用 \$x,才有辦法傳欄位值成功(註:在 awk 內變數值無須加 $,如此例的sum。僅要取得欄位值才有 $1,$2...),END{}之內便是印出求平均值公式。 */
sigma=`awk -v x=$col -v y=$mean '{sum+=((\$x-y)^2)}END{print sqrt(sum/(NR-1))}' $dfile`
/* 為利用 awk 可進行較多的數學運算優勢,如上一指令傳入欄位變數,並利用上一指令計算出的平均值當外部變數傳入,在代入 {},為求該欄位各數值與平均值所產生的差異平方之總和,最後在 END{}內產生所求出的標準差(註:為按照標準差公式來寫該指令,為何如此算,請參考上兩段落所引用的 wikipeida, standard deviation ) */
最後,使用 case 指令,必搭配 esac 結束,如利用 if 指令,必用 fi 結束,for ;do 指令,必用done節速。且很重要的一點,在撰寫script的過程中,很多讀者一定會遇到 ` `,' '," ",空格,所產生的問題,以下再加強說明:
` la -l ~/Desktop ` #為直接執行這指令,標準輸出為指令執行後的結果,前後空格不影響。
' \n123$ab ' #標準輸出就是 \n123$ab 這個字串 \n 前跟 b 後的一個空格皆保留 。
" \n123$ab " /* 假如前面已有宣告 ab=4,則此標準輸出為,空一格,接著至下一行顯示1234 */
在本章,筆者給的資訊量相當的多,主要由於shell script可以完成的自動化工作方法,相當的多,故僅就利用 shell 指令的集結,便也能做到很多編譯程式(如 Fortran, C 等)能做的事,且不需要再透過編譯與連結,當然,在運算時間效率無法相比,但不在此探討。若需要完整程式功能或數學運算功能,我們也透過 awk 這程式語言來進行補強我們的 shell script 指令,awk 可分為 BEGIN{ },{ },END{ },三段落的描述。在我們例子應用上,BEGIN{}內僅表執行第一次,通常拿來宣告初始值,{}內則是會執行資料所有列數(rows),直到檔案尾<EOF>(https://en.wikipedia.org/wiki/End-of-file),可以拿來做迴圈運算,END{}內譯為執行最後一次,通常拿來統整上兩{}區塊運算的最後數值。建議要深入了解 awk 能力的讀者,可以閱讀 gnu awk maunal,http://www.gnu.org/software/gawk/manual/gawk.html,讀完應該會發現,真的是好強大直譯式程式語言阿,尤其拿來對付欄位式的ASCII資料,如 CSV (comma/blank separated values)格式。
阿!?健忘的筆者,竟然忘記寫上很多程式語言的重要方法之一,函式,我們在前章的 /etc/profile 有看見耶...。既然如此,筆者就把它列在下一節貳章之貳,來舉例說明吧!
If you have any feedback or question, please go to my forum to discuss.

(圖2-1)
圖 2-1第一個指令輸入 for 的宣告,後面接著 seq 為變數名稱,為了逐次接收 in 後面之陣列值(http://www.gnu.org/software/bash/manual/html_node/Arrays.html)(註:若加了 ; 則 do 便可寫在同一行),接著 > 的提示字元的等待輸入,便是還沒遇到 done 指令來結束 do 的動作,控制此提示字元的環境變數為 PS2。,此例的 seq 值,依序為第一次讀入 first 字串並存入變數 seq 當其值,接著second、third,從 echo $seq 可以看出,接著設定一個變數 file 其值為 my開頭字串,緊接變數值 $seq(first、second、third),再接固定的 script.sh 字串,接著利用echo指令,印出變數值$file,檢查是不是我們預期的字串值(註:如果想要暫停,讓使用者可以看清楚再繼續,可以加上指令sleep 3,表示畫面停止三秒鐘),接著利用 touch 指令產生 $file 字串值的檔案,再將其利用 chmod 指令,u+x 參數為令僅創立此檔的使用者帳號可執行(若要改為同群組可執行,參數需改為 g+x)。故可看到第二個指令輸入 ls,便列出自動批次產生的shell執行檔了。
以上其實就是 Shell Script 的程式設計之一,只是我們利用Terminal的互動介面。若要把指令全部打完,再一次執行完成,顯示要的結果呢?那就是把它們放在可執行檔案,再直接執行,或是利用 source 的方式執行,也就是所謂的script(中國都稱腳本兒,台灣一般稱指令稿),我們馬上就來試一試吧!
首先,為了確認待會的Script有執行成功,請利用指令 rm -f my*script.sh ( * 號代表my 與 script.sh字串之間無論間隔多少字元的檔名,都屬於此類,需被刪除。若要精確字元數,請使用 ?,一個 ? 代表間隔一個字元),刪除剛剛產生的.sh檔,並且利用指令 vim pro_script.sh,來產生檔名稱為 prod_script.sh 的 script檔,並在裡面鍵入上面的圖2-1所用的指令,如圖2-2
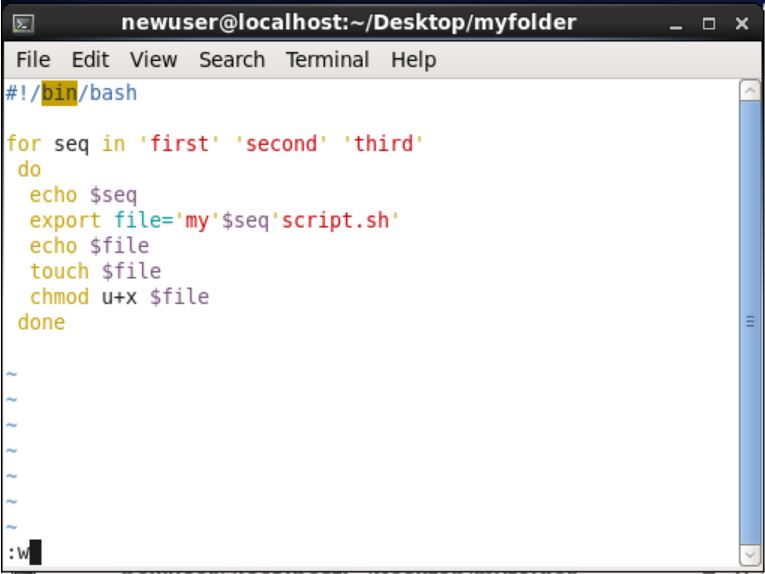
(圖2-2)
儲存上圖離開後,再利用指令 chmod u+x prod_script.sh ,即可在命令提示字元下鍵入 ./prod_script.sh 執行,若是只想直接打 prod_script.sh ,請讀者記得要在 ~/.bash_profile 下,加入 export PATH=$PATH: . ,. 表示把現在的位置,亦加入搜尋路徑內,export宣告環境變數,自訂變數無需加宣告保留字。(2021.10.07更正export說明,以下自訂變數宣告請直接去除export開頭)
眼尖的讀者會發現,為何圖2-2會出現第一行的字串,其實這是 Script 很重要的初始宣告,宣告給電腦系統知道,以下皆使用 bash 的指令或語法完成。若無此宣告,通常需要使用 bash prod_script.sh ,才有辦法執行你撰寫的 Script。往後的範例,只要是循序跳動的數字值,其變數名稱會如一般程式設計習慣,使用 i 、j、k 來代表 ,以防止跟 Shell 保留字或指令衝突,如 seq 其實為 shell 內的指令。利用指令 seq 1 10,則會產生 1 2 3 4 5 6 7 8 9 10,的數列,讀者可以自行 man seq 來了解詳細參數。
接著我們再試著產生今年度(2016)的所有天,每天一個資料夾,每個資料夾內,放入以時間為檔名的資料檔,資料內容為隨機產生的時間序列資料,結果如圖2-3-1,script為圖2-3-2,為了說明方便,筆者另用加了行號的圖2-3-3來說明,除顯示行數與顏色,與圖2-3-2內容皆同。

(圖2-3-1)

(圖2-3-2)

(圖2-3-3)
圖2-3-3第1行為宣告何種 shell,第3、4行為利用 date 指令,來產生我們要的表示方式,並分別指派給 yr 與 ed 變數,說明如下:(export為宣告環境變數),我們直接變數名稱=變數值,請記得=的兩邊,千萬不能有空格
yr=`date +%Y -d "now"`
/* 利用date指令與參數 +% 格式化輸出,+%Y 是印出西元年全部數字,2016,而非16 ( 僅列出後兩數字要換成 +%y ),並利用 -d 參數來使用字串指定各種日期,若是現在時間,則亦可以不需使用 -d "now",使用此指令需確認是否系統時間跟網路標準時間(https://en.wikipedia.org/wiki/Network_Time_Protocol)一致。export 亦可換為 let 或 declare */
ed=`date +%j -d "$yr/12/31"`
/* 可指定日期為今年度的12/31,且要格式化輸出 Day of Year,因2016為閏年,故 ed 的值為 366,-d 參數所接的字串值,可以如以英文表達來獲得日期,如$date %Y-%m-%d -d "100 days ago",可以得到今天(2016-6-1)的100天前為(2016-02-22)。常用的 +% 參數有, +%D 直接列出 month/day/year,+%H:%M:%S,可以列出 hour:minute:second,%s (小寫),為列出從1970-01-01到目前的秒數,通常拿來做 timestamp以辨別不同時間的工作所產生的結果。這對於學術界的資料處理,是很重要也常用的指令,有興趣的讀者,可以藉由 man date ,來了解更多參數與應用。 */
第6到8行,為防止在現在路徑下,已經有 $yr (2016)當名稱的資料夾,故屬於防呆判斷(例外處理),跟18到20行、第26到28行大同小異,只是判斷資料夾存在的參數為 -d ,判斷檔案存在的參數為 -f。
接著利用 cd 進入資料夾。再接著,我們要先產生 "$yr.$ed "為名稱的資料夾,如 2016.001,連續產生到2016.366,所以第11行的 for 迴圈為利用 seq 指令,產生1到366的數字,並逐次把數字當成變數 i 的值,且為了要維持三個字元讓排序可以完全依照 001 至 366,故第13行使用 printf 指令,把 i 的值格式化成三個字元值,並若為1-10則補上1個0,若為11-99則補上2個0。
第14行,為筆者習慣把指令的變數值,可以來除錯,是否為預期的變數值,故確認無誤後,就用 # 讓 echo 失效,然後再進入已產生的 $yr.$ed 。
我們再利用指令來產生我們要的兩個檔案 "$yr.$doy.TS.data"、"$yr.$doy.TS.Norm.data",如2016.001.TS.data、2016.001.TS.Norm.data,內容為四個欄位,分別為時間(0 - 1秒,以0.01為間隔)、x方向的位移、y方向的位移、z方向的位移(以上位移皆利用 $RANDOM 亂數變數產生,該變數可產生 0 ~ 32767 的正整數,利用 % (取餘數)的運算,就產生位移為 0~10 的值(第32到34行),再利用複寫的轉向子 >> 逐一累加入檔案 "$yr.$doy.TS.data" )。第30行至第54行,便是 for 迴圈利用 seq 指令,產生時間 0至 1秒的101筆紀錄值(如圖2-4,為利用 LibreOffice Calc 軟體,畫出 2016.001.TS.Norm.dat 內,分別在 x、y、 z 方向隨時間的(亂數)位移,因各方向數值已經對本身數值群組的最大值做正規化(normalize),如圖2-3-3第45行,故位移數值皆落在0 ~ 1 之間,未正規畫前的數值存放於 2016.001.TS.dat )。
第38到40行,便是利用排序指令 sort,並配合 head 指令來找尋最大值,說明如下:
xmax=`awk '{print $2}' $dfile | sort -nr | head -1` /* 為利用 awk 將檔案名稱為變數值 "$dfile" 內的第二欄位資料印出,並傳給 sort 利用參數 -n (數字排序),-r (由大至小),排完後,再把排序結果傳給 head 指令,利用參數 -1 (hyphen one)(也可用 -n 1),來印出第一個值,此值為最大值,其他找 y、z 最大值亦利用同方式 */
第44到45行,為將找到的最大值,對原本的數值做正規化至0 ~ 1 之間的數值,再利用轉向子 >,一次寫入變數檔案名稱 "$ndfile",說明如下:
eol=`cat $dfile | wc -l` # 利用 cat 與指令 wc -l 來計算檔案內容總行數
awk -v a=$xmax -v b=$ymax -v c=$zmax -v l=$eol '(NR<=l) {printf \
"%5.2f%7.4f%7.4f%7.4f\n" ,$1,$2/a,$3/b,$4/c}' $dfile > $ndfile
/* 上方多的符號 \ ,僅因指令太長,故用此符號銜接。awk 可以利用參數 -v 來傳遞 shell 的變數值,變成 awk 的變數值,故本例可替換成 awk 的變數 a、d、c。NR為 awk 的保留字,代表著現在讀取的行數,因 awk會從檔案內容第一行開始讀取,故筆者設定讓它讀到最後一行後,接著利用格式化 prinf 列出( %5.2f為第一欄印出值形式為浮點數(就是包含小數點的數值,資訊科學裡一般稱為floating point(https://en.wikipedia.org/wiki/Floating_point),往後不再贅述),共 5 個字元,包含小數點後顯示 2 個字元,故 %7.4f,共7個字元,包含小數點後顯示4個字元),\n 為斷行字元(new line),隨後,第1欄,第2欄除以第2欄最大值,第3欄除以第3欄最大值,第4欄除以第4欄最大值,接著把結果一次寫入 $ndifle,若想同時將結果列在螢幕畫面,與寫入檔案,可將 > 指令改為 | tee ,就可以同時顯示螢幕( stdout/1,https://en.wikipedia.org/wiki/Standard_streams)與檔案 */
第47到51行,為利用 awk 指令求平均值,先利用累加方式求如第一欄總和 sum+=$1 (為 sum=sum+$1 表示法,在很多程式設計語言常用 ),在END 後,NR便為讀取的最後行,故直接將總和 sum 除以 NR得到平均數值,因僅測試,故筆者便將其 #,使指令無作用。
接著第53行與第56行為跳出兩層資料夾,使執行script結束後,回到原本執行的路徑下,第57行就令其印出如"執行完畢"的字串(說實在,大部分是耍帥用,就端看讀者個人心情)。

(圖2-4)
經由上面的經驗,看起來找數值陣列的最大、最小、平均等基本統計值,似乎很常用到,那我們就來寫一個 script,可以讓我們可以藉由給定參數 (資料檔案名,資料第幾欄數值,需算何種統計值),把這些常用的計算函數統整,並可以依使用者需求選擇,來印出我們要的計算結果,如圖2-5。

圖2-5大致上可以分成6個區塊(block)來說明,承上述,為了達到可以重複使用來直接計算一群數的最大值、最小值、平均數、標準差,筆者設計了一個 cal_statis.sh 的 script,並用指令 chmod u+x cal_statis.sh 與設定 export PATH=$PATH:~/Desktop/myfolder,詳細便不再贅述了,直接看 cal_statis.sh 的內容。最上方第一行為宣告,之後篇章也都不贅述。
第 1 區塊為,執行 cal_statis.sh 與接其後面的參數數目為 3 個,為了確保使用者輸入參數數目為 3 個,則使用指令 if [ $# != 3 ] 來判斷,在此的 # 代表標準輸入(stdin,如利用鍵盤輸入)的數目,其值便為 $#,並非說明,請讀者要熟記。當數目值不等於 ( != ) 3,便印出說明再利用指令 exit 跳出 script 。(註:$# 如一般程式語言裡的 argc(argument count),而 $1,則為一般程式語言裡的 argv[1] (argument variable, index 1)。$# 用來計算外部輸入的參數數目,$1 為接收輸入的參數值,$0 為shell 的檔案名字 ),其他 $ 特殊用法,如 $$ 代表 shell 的 PID(process ID),$! 為最後一個背景執行工作的 PID,$?為最後執行的命令返回值,$* 與 $@ 為方別用"..."與" "..." "..." "的不同方式印出參數值。
第 2 區塊為宣告標準輸入的值,可以當成那些變數值,第 1 個輸入給 "$dfile",代表要操作的 資料檔名,第 2 輸入給 "$col",代表要操作的資料欄位,第 3 個輸入給 "$method",代表要使用的計算方法。
第 3 區塊為防止例外錯誤,僅為了防止輸入錯誤的檔案路徑。
第 4、5 區塊亦分別為防止欄位數非數字,與大於最大欄位數而發生程式執行錯誤,說明如下
if [ ! -n "$(echo $col | sed -n '/^[0-9]\+$/p')" ]
/* 為利用 -n 判斷是否空值,接著為利用 sed 的搜尋但不取代的能力,sed環境內參數 -n 為安靜模式,搜尋條件從 ' 開始,條件給在 / / 之間, ^[0-9] 為搜尋起頭為數字,接著 \+ 為後面接著的字元也是要數字(註:請參閱 Basic RE 與 Extended RE 的差異,https://www.gnu.org/software/grep/manual/html_node/Basic-vs-Extended.html),再來比對到 $ ,代表結尾也要是數字;p為 sed 的命令,表示若有符合搜尋條件,則印出數值。讀者看到這裡,可以回想一下前面章節,是否很像提過的正規表示式的方式呢? */
fn=`awk 'END{print NF}' $dfile` #利用 awk 的END{},來印出最後一行的欄位總數NR
if [ $col -gt $fn ] #若從外部輸入的數字,大於欄位總數,則接著印出錯誤訊息,並離開script
接著用 echo 印出 $dfile $col $method 值的指令,已用 # 變成說明,這提醒讀者寫程式時,留個好習慣。進入主要程式處理前,要先測試所得到的變數值,是否皆是你的預期值,不然垃圾參數輸入,垃圾結果輸出 (Garbage in,Garbage out)。
第 6 個區塊,為 case 指令的宣告,一般用於關鍵字的判斷與分類處理,筆者在此僅分成 max、min、avg、stdev,若不屬於上述四類,則會跳至 * 類別,並印出錯誤訊息。max 與 min 類別,分別計算最大與最小值,計算的方式在上一個 script 有說明,min 僅差在 sort 參數只用 -n,便為預設將數列從小排到大。avg 類別為計算數列平均值,上一個 script 亦有說明,便不在贅述,stdev類別則用來計算標準差(standard deviation, https://en.wikipedia.org/wiki/Standard_deviation),說明如下:
mean=`awk -v x=$col '{sum+=\$x}END{print sum/NR}' $dfile`
/* 利用 awk -v 來傳遞外部變數,當成 awk {}內運算的欄位變數,故請讀者注意要用 \$x,才有辦法傳欄位值成功(註:在 awk 內變數值無須加 $,如此例的sum。僅要取得欄位值才有 $1,$2...),END{}之內便是印出求平均值公式。 */
sigma=`awk -v x=$col -v y=$mean '{sum+=((\$x-y)^2)}END{print sqrt(sum/(NR-1))}' $dfile`
/* 為利用 awk 可進行較多的數學運算優勢,如上一指令傳入欄位變數,並利用上一指令計算出的平均值當外部變數傳入,在代入 {},為求該欄位各數值與平均值所產生的差異平方之總和,最後在 END{}內產生所求出的標準差(註:為按照標準差公式來寫該指令,為何如此算,請參考上兩段落所引用的 wikipeida, standard deviation ) */
最後,使用 case 指令,必搭配 esac 結束,如利用 if 指令,必用 fi 結束,for ;do 指令,必用done節速。且很重要的一點,在撰寫script的過程中,很多讀者一定會遇到 ` `,' '," ",空格,所產生的問題,以下再加強說明:
` la -l ~/Desktop ` #為直接執行這指令,標準輸出為指令執行後的結果,前後空格不影響。
' \n123$ab ' #標準輸出就是 \n123$ab 這個字串 \n 前跟 b 後的一個空格皆保留 。
" \n123$ab " /* 假如前面已有宣告 ab=4,則此標準輸出為,空一格,接著至下一行顯示1234 */
在本章,筆者給的資訊量相當的多,主要由於shell script可以完成的自動化工作方法,相當的多,故僅就利用 shell 指令的集結,便也能做到很多編譯程式(如 Fortran, C 等)能做的事,且不需要再透過編譯與連結,當然,在運算時間效率無法相比,但不在此探討。若需要完整程式功能或數學運算功能,我們也透過 awk 這程式語言來進行補強我們的 shell script 指令,awk 可分為 BEGIN{ },{ },END{ },三段落的描述。在我們例子應用上,BEGIN{}內僅表執行第一次,通常拿來宣告初始值,{}內則是會執行資料所有列數(rows),直到檔案尾<EOF>(https://en.wikipedia.org/wiki/End-of-file),可以拿來做迴圈運算,END{}內譯為執行最後一次,通常拿來統整上兩{}區塊運算的最後數值。建議要深入了解 awk 能力的讀者,可以閱讀 gnu awk maunal,http://www.gnu.org/software/gawk/manual/gawk.html,讀完應該會發現,真的是好強大直譯式程式語言阿,尤其拿來對付欄位式的ASCII資料,如 CSV (comma/blank separated values)格式。
阿!?健忘的筆者,竟然忘記寫上很多程式語言的重要方法之一,函式,我們在前章的 /etc/profile 有看見耶...。既然如此,筆者就把它列在下一節貳章之貳,來舉例說明吧!
If you have any feedback or question, please go to my forum to discuss.